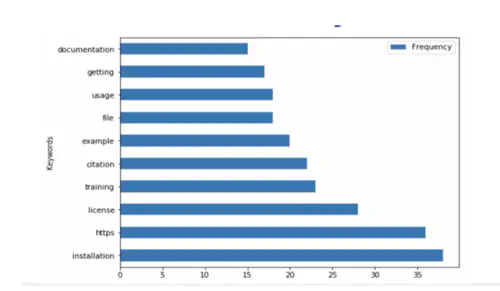
Data science projects require knowledge of software that changes rapidly. As a result, scientists spend hours reading long documentations and manuals instead of advancing their scientific fields. In this project, we aim to automatically extract relevant aspects of scientific software (e.g., what does it do, how to install it, how to operate with it or how to cite it) from documentation and code using machine learning techniques. The students will build on an existing baseline of classifiers and try to improve the existing results.